
On OpenAI’s Model Naming Scheme
Hey ChatGPT, help me name my models
 Good to see you too, ChatGPT.
Good to see you too, ChatGPT.
Last week, OpenAI announced two new flagship reasoning models: o3 and o4-mini, with the latter including a “high” variant. The names were met with outrage across the internet, including from yours truly, and for good reason. Even Sam Altman, the company’s chief executive, agrees with the criticism. But generally, the issue isn’t with the letters because it’s easy to remember that if “o” comes before the number, it’s a reasoning model, and if it comes after, it’s a standard “omnimodel.” “Mini” means the model is smaller and cheaper, and a dot variant is some iteration of the standard GPT-4 model (like 4.5, 4.1, etc.). That’s not too tedious to think about when deciding when to use each model. If the o is after the number, it’s good for most tasks. If it’s in front, the model is special.
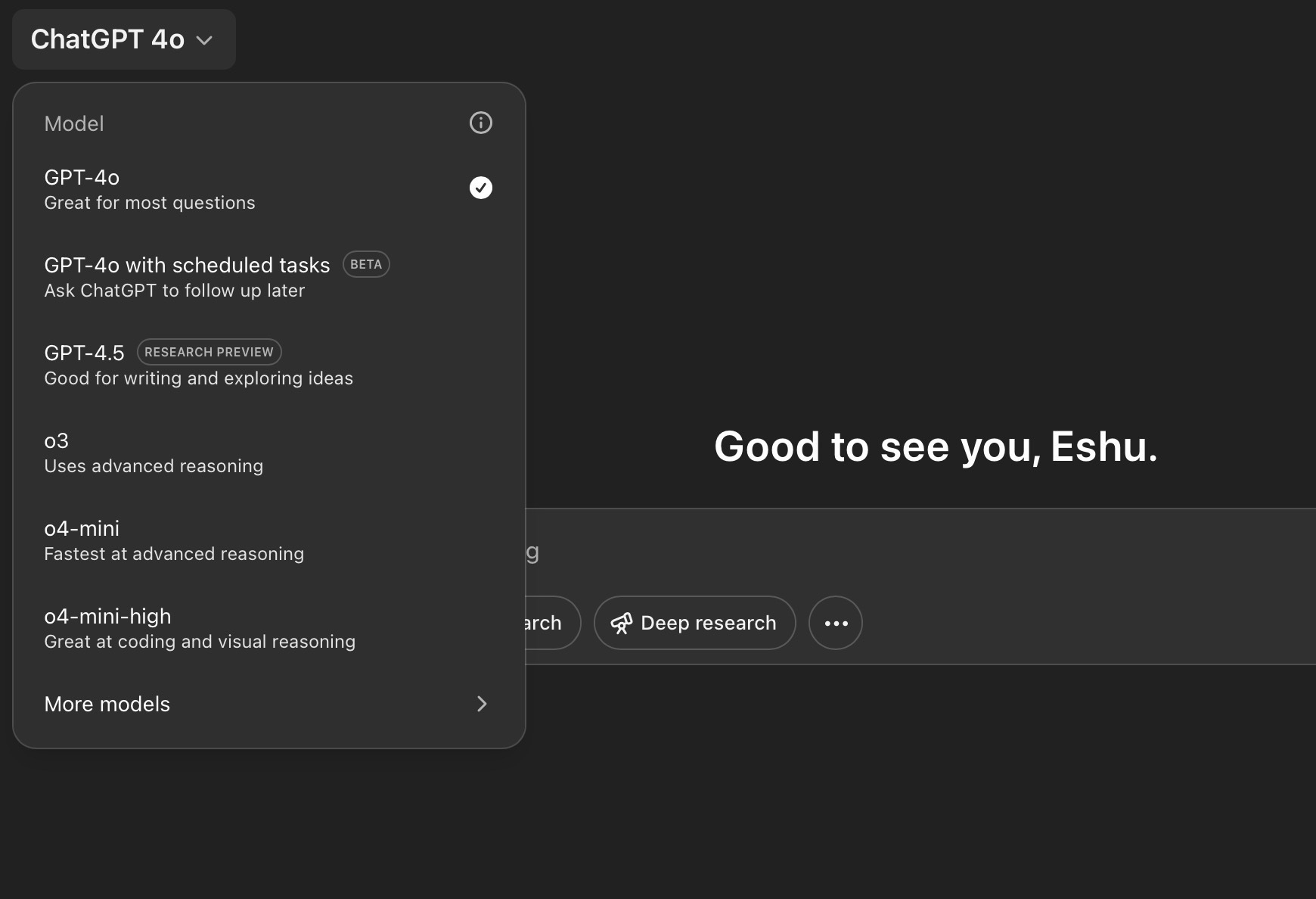
The confusion comes between OpenAI’s three reasoning models, which the company describes like this in the model selector on the ChatGPT website and the Mac app:
- o3: Uses advanced reasoning
- o4-mini: Fastest at advanced reasoning
- o4-mini-high: Great at coding and visual reasoning
This is nonsensical. If the 4o/4o-mini naming is to be believed, the faster version of the most competent reasoning model should be o3-mini, but alas, that’s a dumber, older model. o4-mini-high, which has a higher number than o3, is a worse model in many, but not all, benchmarks. For instance, it earned a 68.1 percent in the software engineering benchmark OpenAI advertises in its blog post announcing the new models, while o3 scored 69.1 percent. That’s a minuscule difference, but it still is a worse model in that scenario. And that benchmark completely ignores o4-mini, which isn’t listed anywhere in OpenAI’s post; the company says “all models are evaluated at high ‘reasoning effort’ settings—similar to variants like ‘o4-mini-high’ in ChatGPT.”
Anyone looking at OpenAI’s model list would be led to believe o4-mini-high (and presumably its not-maxed-out variant, o4-mini) would be some coding prodigy, but it isn’t. o3 is, though — it’s the smartest of OpenAI’s models in coding. o3 also excels in “multimodal” visual reasoning over o4-mini-high, which makes the latter’s description as “great at… visual reasoning” moot when o3 does better. OpenAI, in its blog post, even says o3 is its “most powerful reasoning model that pushes the frontier across coding, math, science, visual perception, and more.” o4-mini only beats it in the 2024 and 2025 competition math scores, so maybe o4-mini-high should be labeled “great at complex math.” Saying o4-mini-high is “great at coding” is misleading when o3 is OpenAI’s best offering.
The descriptions of o4-mini-high and o4-mini should emphasize higher usage limits and speed, because truly, that’s what they excel at. They’re not OpenAI’s smartest reasoning models, but they blow o3-mini out of the water, and they’re way more practical. For Plus users who must suffer OpenAI’s usage caps, that’s an important detail. I almost always query o4-mini because I know it has the highest usage limits even though it isn’t the smartest model. In my opinion, here’s what the model descriptions should be:
- o3 Pro (when it launches to Pro subscribers): Our most powerful reasoning model
- o3: Advanced reasoning
- o4-mini-high: Quick reasoning
- o4-mini: Good for most reasoning tasks
To be even more ambitious, I think OpenAI could ditch the “high” moniker entirely and instead implement a system where o4 intelligently — based on current usage, the user’s request, and overall system capacity — could decide to use less or more power. The free tier of ChatGPT already does this: When available, it gives users access to 4o over 4o-mini, but it gives priority access to Plus and Pro subscribers. Similarly, Plus users ought to receive as much o4-mini-high access as OpenAI can support, and when it needs more resources (or when a query doesn’t require advanced reasoning), ChatGPT can fall back to the cheaper model. This intelligent rate-limiting system could eventually extend to GPT-5, whenever that ships, effectively making it so that users no longer must choose between models. They still should be able to, of course, but just like the search function, ChatGPT should just use the best tool for the job based on the query.
ChatGPT could do with a lot of model cleanup in the next few months. I think GPT-4.5 is nearly worthless, especially with the recent updates to GPT-4o, whose personality has become friendlier and more agentic recently. Altman championed 4.5’s writing style when it was first announced, but now the model isn’t even accessible from the company’s application programming interface because it’s too expensive and 4.1 — whose personality has been transplanted into 4o for ChatGPT users — smokes it in nearly every benchmark. 4.5 doesn’t do anything well except write, and I just don’t think it deserves such a prominent position in the ChatGPT model picker. It’s an expensive, clunky model that could just be replaced by GPT-4o, which, unlike 4.5, can code and logic its way through problems with moderate competency.
Similarly, I truly don’t understand why “GPT-4o with scheduled tasks” is a separate model from 4o. That’s like making Deep Research or Search a new option from the picker. Tasks should be relegated to another button in the ChatGPT app’s message box, sitting alongside Advanced Voice Mode and Whisper. Instead of sending a normal message, task requests should be designated as so.
Of the major artificial intelligence providers, I’d say Anthropic has the best names, though only by a slim margin. Anyone who knows how poetry works should have a pretty easy time understanding which model is the best, aside from Claude 3 Opus, which isn’t the most powerful model but nevertheless carries the “best” name of the three (an opus refers to a long musical composition). Still, the hate for Claude 3.7 Sonnet and love for 3.5 Sonnet appear to add confusion to the lineup — but that’s a user preference unperturbed by benchmarks, which have 3.7 Sonnet clearly in the lead.
Gemini’s models appear to have the most baggage associated with them, but for the first time in Google’s corporate history, I think the company named the ones available through the chatbot somewhat decently. “Flash” appears to be used for the general-use models, which I still think are terrible, and “Pro” refers to the flagship ones. Seriously, Google really did hit it out of the park with 2.5 Pro, beating every other model in most benchmarks. It’s not my preferred one due to its speaking style, but it is smart and great at coding.